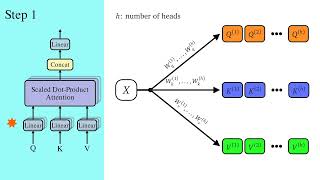
Media Summary: In this video, I will first give a recap of Scaled Dot-Product Transformers are notoriously resource-intensive because their self- A complete, section-by-section walkthrough of "
1 Minute Paper Higher Order Linear Attention Explained - Detailed Analysis & Overview
In this video, I will first give a recap of Scaled Dot-Product Transformers are notoriously resource-intensive because their self- A complete, section-by-section walkthrough of "