Media Summary: SpanBERT: Improving Pre-training by Representing and Predicting Spans Course Materials: ... ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators Course Materials: ... Rethinking Attention with Performers Course Materials:
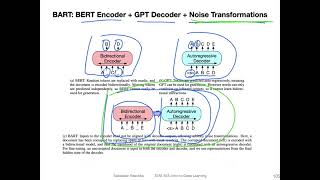
Bart Lecture 56 Part 4 Applied Deep Learning Supplementary - Detailed Analysis & Overview
SpanBERT: Improving Pre-training by Representing and Predicting Spans Course Materials: ... ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators Course Materials: ... Rethinking Attention with Performers Course Materials: Reformer: The Efficient Transformer Course Materials: Don't Stop Pretraining: Adapt Language Models to Domains and Tasks Course Materials: ... Improving Language Understanding by Generative Pre-Training Course Materials: ...
Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention Course Materials: ... Attention Is All You Need Course Materials: