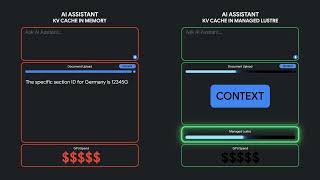
Media Summary: Myeongjae Jeon, UNIST and Microsoft Research; Shivaram Venkataraman, University of Wisconsin and Microsoft Research; ... Managed Lustre helps LLMs reload saved context instead of recalculating expensive analysis from scratch. This video explains ... Many ML and big data teams in the open source community are looking to run their workloads in the cloud and they invariably ...
Runtime Aware Gpu Scheduling For Multi Tenant Dnn Inference - Detailed Analysis & Overview
Myeongjae Jeon, UNIST and Microsoft Research; Shivaram Venkataraman, University of Wisconsin and Microsoft Research; ... Managed Lustre helps LLMs reload saved context instead of recalculating expensive analysis from scratch. This video explains ... Many ML and big data teams in the open source community are looking to run their workloads in the cloud and they invariably ... Don't miss out! Join us at our next KubeCon + CloudNativeCon events in Mumbai, India (18-19 June, 2026), Yokohama, Japan ... vCluster** (Virtual Cluster) provides a solution to the "too many clusters" problem by offering a lightweight, isolated control plane ... USENIX ATC '23 - Decentralized Application-Level Adaptive
Modern AI systems process millions or even hundreds of millions of requests per second, and Lightning talk for the USENIX ATC '19 paper "Analysis of Large-Scale In this screencast, we show how OpenNebula can be used to run a Most DevOps engineers deploy their first LLM on Kubernetes the same way they deploy a Node.js service — and then spend ... In this webinar, you'll explore proven architectures for building Is your AI model fast enough for real users? In Part 3 of our AI Infrastructure series, we master Real-Time
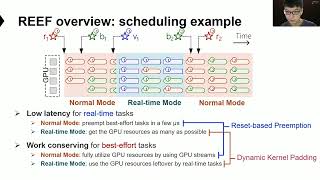
OSDI '22 - Microsecond-scale Preemption for Concurrent