Media Summary: Institute for Quantitative Biomedicine Spring 2026 Seminar Series Week 6. Hosted at Rutgers, The State University of New Jersey. ARC-AGI-3 from the ARC Prize measures intelligence by testing learning efficiency across 135 interactive visual games. This lecture discusses the critical shift from
Why Benchmarks Matter Building Better Ai Evaluation Frameworks - Detailed Analysis & Overview
Institute for Quantitative Biomedicine Spring 2026 Seminar Series Week 6. Hosted at Rutgers, The State University of New Jersey. ARC-AGI-3 from the ARC Prize measures intelligence by testing learning efficiency across 135 interactive visual games. This lecture discusses the critical shift from Want to play with the technology yourself? Explore our interactive demo → Learn more about the ... The provided text outlines the historical shift in generative Speakers: Elena Adamantidou, Daniel Aschauer, Mark Cieliebak, Katsiaryna Mlynchyk, Daniel Neururer, Alexandros Paramythis, ...
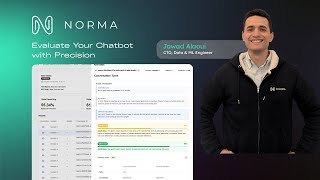
The provided text introduces ITBench, a comprehensive Jawad Alaoui Norma's CEO lays out the toughest obstacle in Join Roche's Healthcare Transformers platform and The London School of Economics and Political Science (LSE) for an essential ...