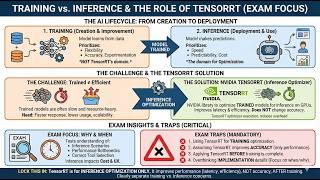
Media Summary: By the end of this lecture, you will be able to: Understand what In many applications of deep learning models, we would benefit from reduced latency (time taken for Contributed Talk at the PL in ML: Polish View on Machine Learning 2018 Conference (plinml.mimuw.edu.pl). Abstract: GPUs are ...
Episode 17 Tensorrt Inference Optimization - Detailed Analysis & Overview
By the end of this lecture, you will be able to: Understand what In many applications of deep learning models, we would benefit from reduced latency (time taken for Contributed Talk at the PL in ML: Polish View on Machine Learning 2018 Conference (plinml.mimuw.edu.pl). Abstract: GPUs are ... Original Youtube video: MLOps Community: Maher is an engineering ... In this vídeo I will show you How to convert a model to Learn from our experts about how we use MTP speculative decoding method to achieve better performance in