Media Summary: Why does ChatGPT or Claude feel instant? Every modern LLM hides one trick that makes token generation 10–100× faster: the ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ...
Kv Cache Explained In 3 Minutes - Detailed Analysis & Overview
Why does ChatGPT or Claude feel instant? Every modern LLM hides one trick that makes token generation 10–100× faster: the ... Try Voice Writer - speak your thoughts and let AI handle the grammar: The Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Don't like the Sound Effect?:* *LLM Training Playlist:* ... Ever wondered how ChatGPT remembers your entire conversation without slowing down? The secret is Same prompt. Same model. The first call costs $1.00. The second costs $0.05. Same words — 20× cheaper. The reason isn't a ...
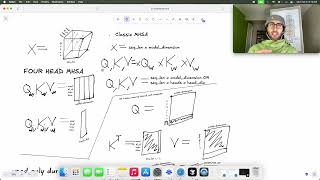
Large Language Models are powerful, but they have a massive bottleneck: memory overhead. When you feed an AI massive ... Have you ever wondered why AI can generate long essays so quickly, word by word? If it had to read the entire essay from scratch ... In this video, I explore the mechanics of Every time you chat with a large language model, a silent computational storm rages inside the GPU. In autoregressive decoding ... The unsung hero that makes LLM inference fast. The hidden data structure that consumes your GPU memory. What it is, why it ... A visual deep-dive into how attention works in modern LLMs — from embeddings and Q, K, V projections to