Page Summary: Ever wonder why neural networks, despite their high accuracy, can be fooled by near-invisible changes to an image? Large language models (LLMs) like ChatGPT, Bard, or Claude undergo ...
Llm Projects Bootcamp Adversarial Attack Project -
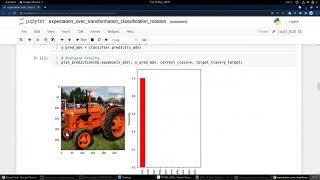
Ever wonder why neural networks, despite their high accuracy, can be fooled by near-invisible changes to an image? Large language models (LLMs) like ChatGPT, Bard, or Claude undergo ...
Important details found
- Ever wonder why neural networks, despite their high accuracy, can be fooled by near-invisible changes to an image?
- Large language models (LLMs) like ChatGPT, Bard, or Claude undergo ...
Why this topic is useful
Readers often search for Llm Projects Bootcamp Adversarial Attack Project because they want a clearer explanation, related examples, and a practical way to continue exploring the topic.
Sponsored
Frequently Asked Questions
How should readers use this information?
Use it as a starting point, then open related pages for more specific details.
What should readers check next?
Readers should check related pages, official references, or updated sources when details matter.
Why are related topics included?
Related topics help readers compare nearby references and understand the broader subject.
Topic Gallery





![[Attack AI in 5 mins] Adversarial ML #1. FGSM](https://i.ytimg.com/vi/4TseynD_v7M/mqdefault.jpg)



Sponsored